
SQL Server 2014 Clustered Columnstore Indexes and Partitioning
(If you attended my talk at SQL Supper in January 2016 and want a copy of my scripts, then this post here has the full details)
One of the features of SQL 2014 which got less column inches (pun intended) than Hekaton/ in memory OLTP but was of more interest to me was the clustered columnstore indexes, or CCI for brevity.
In some ways CCI is the next step on from non clustered columnstore indexes (NCCI) which was released in SQL Server 2012. I say in some ways because
Columnstores store the data in row-groups batches of 1048576 rows. Row groups can be in 4 different states at any one time:
When a delta store has been compressed the state is changed to COMPRESSED. A row store is not directly up-datable. So when we UPDATE or DELETE a row that is stored in a COMPRESSED row group the row itself is not affected. w/r/t a DELETE the row to be deleted is marked for deletion in a delete bitmap. w/r/t an UPDATE the row to be updated is marked for deletion in a delete bitmap and a new row is inserted in an OPEN row group. The task of cleaning up these deleted rows is not managed by the db engine; a re-build of the index is required to remove the rows marked for deletion. Performance will deteriorate if these rows are not purged and data not re-organised.
INVISIBLE is a transitory state between CLOSED and COMPRESSED. The invisible state is when the Tuple Mover is in the process of compressing a closed delta store. During this phase the Tuple Mover does not prevent the data from being read, and inserts are not blocked, but UPDATES and DELETES are. The Tuple Mover compresses closed delta-stores into row-groups and runs as a background process roughly every 5 minutes.
There are a some catalog views we can use to inspect the CCI’s. I’ll focus on these more later.
select * from sys.column_store_dictionaries;
select * from sys.column_store_segments;
select * from sys.column_store_row_groups;
The below example creates a new table and CCI and inserts over 2 millions rows and executes the 3 views.
use msdb
--**************************************
--CCI Inserts
--**************************************
-- Table definition
create table [dbo].[CciDemo](
[Id] [int] NOT NULL,
[WatchDate] [date] NOT NULL,
[associateId] [bigint] NOT NULL,
[ObjectKey] [varchar] (4) NOT NULL,
[value] [float] NOT NULL
)
GO
-- Creating our Clustered Columnstore Index
create clustered columnstore index CCI_CciDemo
on dbo.CciDemo;
GO
-- Insert the rows
declare @i as int;
set @i = 1;
begin tran
while @i <= 2058578
begin
insert into dbo.CciDemo
( [Id], [WatchDate], [associateId],[ObjectKey],[value] )
values
( 1234, GETDATE(), RAND ()*12, 'FFOS', RAND ()*13)
set @i = @i + 1;
end;
commit;
--what do the catalog views show us?
select * from sys.column_store_dictionaries;
select * from sys.column_store_segments;
select * from sys.column_store_row_groups;
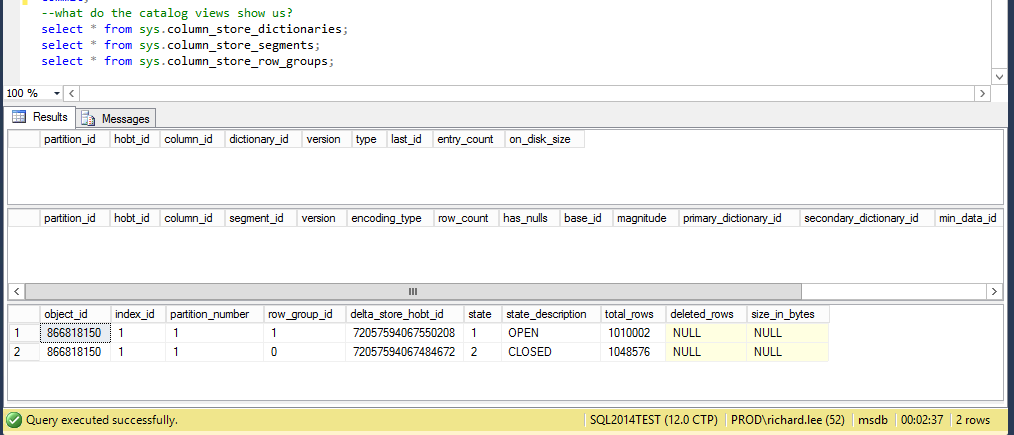
The views show us that 2 delta groups have been created; 1 closed and 1 open, whilst the other views return nothing. This is because these catalog views report on objects that only pertain to row groups.
At this point, we can wait for the Tuple Mover to run and compress the closed delta stores into row groups, or we can rebuild the index. Let’s rebuild the index
--rebuild the table
alter table dbo.CciDemo
rebuild
--tuple mover would come and compress the closed delta stores
Now check the views again:
--now what do the catalog views show us?
select * from sys.column_store_dictionaries;
select * from sys.column_store_segments;
select * from sys.column_store_row_groups;
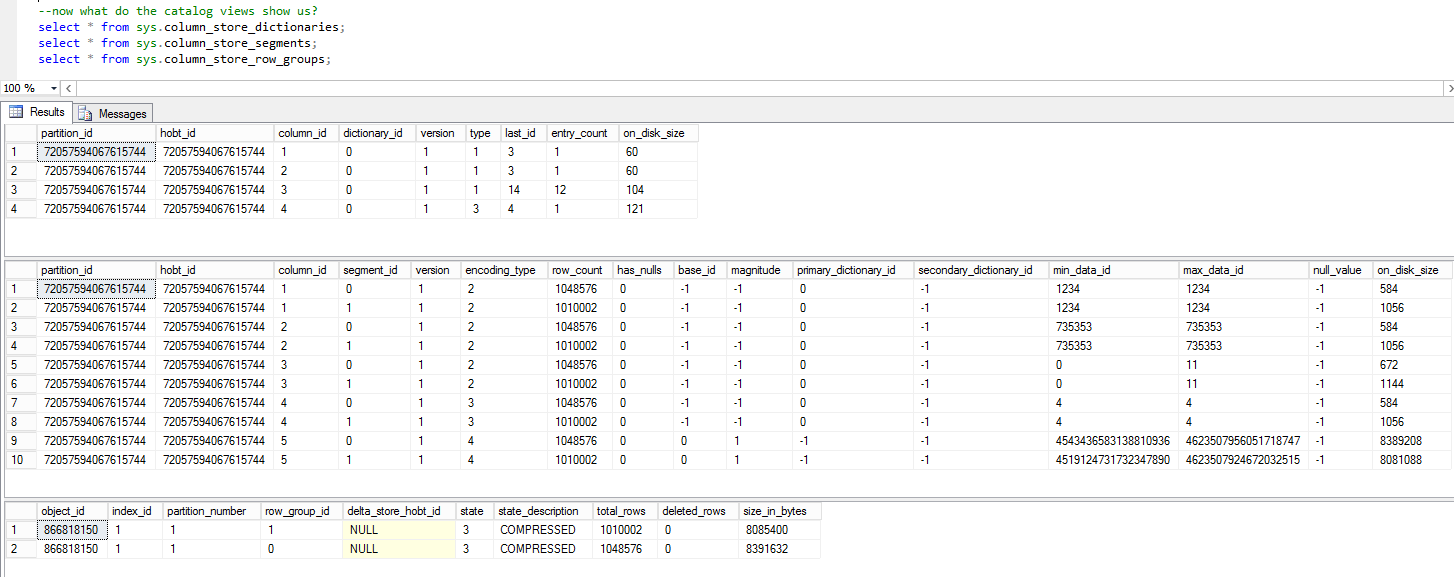
So now the delta stores have been compressed into row groups. And now we have dictionaries and segments.
CREATE DATABASE [Phoebix]
CONTAINMENT = NONE
ON PRIMARY
( NAME = N'Phoebix', FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL12.MSSQLSERVER\MSSQL\DATA\Phoebix.mdf' , SIZE = 5120KB , FILEGROWTH = 1024KB )
LOG ON
( NAME = N'Phoebix_log', FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL12.MSSQLSERVER\MSSQL\DATA\Phoebix_log.ldf' , SIZE = 2048KB , FILEGROWTH = 10%)
GO
ALTER DATABASE [Phoebix] SET COMPATIBILITY_LEVEL = 120
GO
ALTER DATABASE [Phoebix] SET READ_WRITE
GO
ALTER DATABASE [Phoebix] SET RECOVERY SIMPLE
GO
ALTER DATABASE [Phoebix] SET MULTI_USER
GO
USE [Phoebix]
GO
IF NOT EXISTS (SELECT name FROM sys.filegroups WHERE is_default=1 AND name = N'PRIMARY') ALTER DATABASE [Phoebix] MODIFY FILEGROUP [PRIMARY] DEFAULT
GO
use Phoebix
go
ALTER DATABASE Phoebix ADD FILEGROUP [FGPhoebix]
ALTER DATABASE Phoebix ADD FILE
(NAME = N'Phoebix_F01', FILENAME = N'S:\Data\PhoebixData\Phoebix1.ndf', SIZE = 5GB, FILEGROWTH = 1GB)
TO FILEGROUP [FGPhoebix]
ALTER DATABASE Phoebix ADD FILE
(NAME = N'Phoebix_F02', FILENAME = N'S:\Data\PhoebixData\Phoebix2.ndf', SIZE = 5GB, FILEGROWTH = 1GB)
TO FILEGROUP [FGPhoebix]
USE Phoebix
GO
CREATE PARTITION FUNCTION pfnPhoebix (int) AS RANGE LEFT FOR VALUES (12116, 12146, 12765, 13258, 13267, 13278, 13441)
GO
USE Phoebix
GO
CREATE PARTITION SCHEME pscPhoebix AS PARTITION pfnPhoebix ALL TO (FGPhoebix)
GO
use Phoebix
go
CREATE TABLE dbo.B_Phoebix
(
Id INT NOT NULL,
MonthEndDate DATE NOT NULL,
memberId BIGINT NOT NULL,
BSKey VARCHAR (4) NOT NULL,
value FLOAT NOT NULL
) ON pscPhoebix (Id) WITH (DATA_COMPRESSION = PAGE);
GO
CREATE TABLE dbo.S_Phoebix
(
Id INT NOT NULL,
MonthEndDate DATE NOT NULL,
memberId BIGINT NOT NULL,
SbId INT NOT NULL,
flow FLOAT NOT NULL,
vesting FLOAT NULL
) ON pscPhoebix (Id) WITH (DATA_COMPRESSION = PAGE);
GO
CREATE CLUSTERED COLUMNSTORE INDEX [B_Custard] ON [dbo].[B_Phoebix] WITH (DROP_EXISTING = OFF)
GO
CREATE CLUSTERED COLUMNSTORE INDEX [S_Custard] ON [dbo].[S_Phoebix] WITH (DROP_EXISTING = OFF)
GO
select * from sys.column_store_dictionaries;
select * from sys.column_store_segments;
select * from sys.column_store_row_groups;
Nothing but empty tables means no row groups dictionaries etc. Now we need data to work with.
In the interest of providing a full working demo I have created some tables with the data that we will load from. The SQL below creates a table with 3 runs we will use in the demos. In real life you’ll be inserting from SSIS or HPC or your data provider of choice at far less than a million rows per insert.
CREATE TABLE dbo.B_Phoebix_Load
(
Id INT NOT NULL,
MonthEndDate DATE NOT NULL,
memberId BIGINT NOT NULL,
BSKey VARCHAR (4) NOT NULL,
value FLOAT NOT NULL
) WITH (DATA_COMPRESSION = PAGE);
GO
CREATE TABLE dbo.S_Phoebix_Load
(
Id INT NOT NULL,
MonthEndDate DATE NOT NULL,
memberId BIGINT NOT NULL,
SbId INT NOT NULL,
flow FLOAT NOT NULL,
vesting FLOAT NULL
) WITH (DATA_COMPRESSION = PAGE);
GO
declare @i as int;
set @i = 1;
begin tran
while @i <= 3200000
begin
INSERT INTO dbo.B_Phoebix_Load (Id, monthEndDate, memberId, bsKey, value)
values
( 13258, GETDATE(), RAND ()*12, 'FFOS', RAND ()*13),
( 13267, DATEADD(MONTH,1,GETDATE()), RAND ()*12, 'FFOS', RAND ()*13),
( 13278, DATEADD(MONTH,2,GETDATE()), RAND ()*12, 'FFOS', RAND ()*13)
INSERT INTO dbo.S_Phoebix_Load (Id, monthEndDate, memberId, sbId, flow, vesting)
values
( 13258, GETDATE(), RAND ()*12, RAND ()*50, RAND ()*13, RAND ()*13),
( 13267, DATEADD(MONTH,1,GETDATE()), RAND ()*12, RAND ()*50, RAND ()*13, RAND ()*13),
( 13278, DATEADD(MONTH,2,GETDATE()), RAND ()*12, RAND ()*50, RAND ()*13, RAND ()*13)
set @i = @i + 1;
end;
commit;
First we create an empty rowset from the table we will ultimately be switching in to.
-- create the empty rowset from the table we will switch into
select top 0 * into dbo.B_Phoebix_13258 from dbo.B_Phoebix
select top 0 * into dbo.S_Phoebix_13258 from dbo.S_Phoebix
Seeing as CCI is the compression method we don’t have to compress the temporary table, but it makes sense to add compression to keep the size of the table, not matter how temporary, to a minimum.
--do ourselves a favour and make this temporary table as small as possible
--and add page compression
ALTER TABLE dbo.B_Phoebix_13258 REBUILD WITH (DATA_COMPRESSION = PAGE)
ALTER TABLE dbo.S_Phoebix_13258 REBUILD WITH (DATA_COMPRESSION = PAGE)
The empty rowset is by default created on the PRIMARY filegroup, so we need to move this by creating an index and specifying the filegroup which the partition we will switch into is stored on.
--empty rowset is created on primary by default
--move to the filegroup the partitioned table is on
ALTER TABLE dbo.B_Phoebix_13258 ADD CONSTRAINT CONS_dbo_B_Phoebix_13258 PRIMARY KEY (Id) on FGPhoebix
ALTER TABLE dbo.S_Phoebix_13258 ADD CONSTRAINT CONS_dbo_S_Phoebix_13258 PRIMARY KEY (Id) on FGPhoebix
Now table is moved, drop index
-- we don't need it (or can even keep it as we are adding CCI)
ALTER TABLE dbo.B_Phoebix_13258 DROP CONSTRAINT CONS_dbo_B_Phoebix_13258
ALTER TABLE dbo.S_Phoebix_13258 DROP CONSTRAINT CONS_dbo_S_Phoebix_13258
Create a contraint on temp tables
--add constraint on temp table so that we can switch in to main table
ALTER TABLE dbo.B_Phoebix_13258 WITH CHECK ADD CONSTRAINT CK_B_Phoebix_13258 CHECK (([Id]=(13258)))
ALTER TABLE dbo.S_Phoebix_13258 WITH CHECK ADD CONSTRAINT CK_s_Phoebix_13258 CHECK (([Id]=(13258)))
Now we insert data into the temporary tables. The data will be stored as a heap currently, which is fine as we will be creating the CCI after importing data. That way it does not matter how many rows are inserted, building the index post insert will optimise the storage and create the dictionaries necessary.
--add data to temp table from loading tables
--remember IRL this would be SSIS or HPC or data loader of choice
INSERT INTO dbo.B_Phoebix_13258 (Id, monthEndDate, memberId, bsKey, value)
select Id, monthEndDate, memberId, bsKey, value
from dbo.B_Phoebix_Load WITH (NOLOCK)
where id = 13258
INSERT INTO dbo.S_Phoebix_13258 (Id, monthEndDate, memberId, sbId, flow, vesting)
select Id, monthEndDate, memberId, sbId, flow, vesting
from dbo.S_Phoebix_Load WITH (NOLOCK)
where id = 13258
If we were to try to switch the partitions in now it would fail as they are not identical: we need to create the CCI on the temporary tables before we switch in.
--if we were to try to switch in now it would fail as no CCI on tmep table
ALTER TABLE dbo.B_Phoebix_13258 SWITCH TO dbo.B_Phoebix PARTITION $PARTITION.pfnPhoebix(13258)
ALTER TABLE dbo.S_Phoebix_13258 SWITCH TO dbo.S_Phoebix PARTITION $PARTITION.pfnPhoebix(13258)

--add CCI
CREATE CLUSTERED COLUMNSTORE INDEX [PK_B_Phoebix_13258] ON dbo.B_Phoebix_13258 WITH (DROP_EXISTING = OFF)
CREATE CLUSTERED COLUMNSTORE INDEX [PK_S_Phoebix_13258] ON dbo.S_Phoebix_13258 WITH (DROP_EXISTING = OFF)
ALTER TABLE dbo.B_Phoebix_13258 SWITCH TO dbo.B_Phoebix PARTITION $PARTITION.pfnPhoebix(13258)
ALTER TABLE dbo.S_Phoebix_13258 SWITCH TO dbo.S_Phoebix PARTITION $PARTITION.pfnPhoebix(13258)
Now the temp table and the tables are identical we can switch in. Checking the views shows all the data is switched in.
select * from sys.column_store_dictionaries;
select * from sys.column_store_segments;
select * from sys.column_store_row_groups;
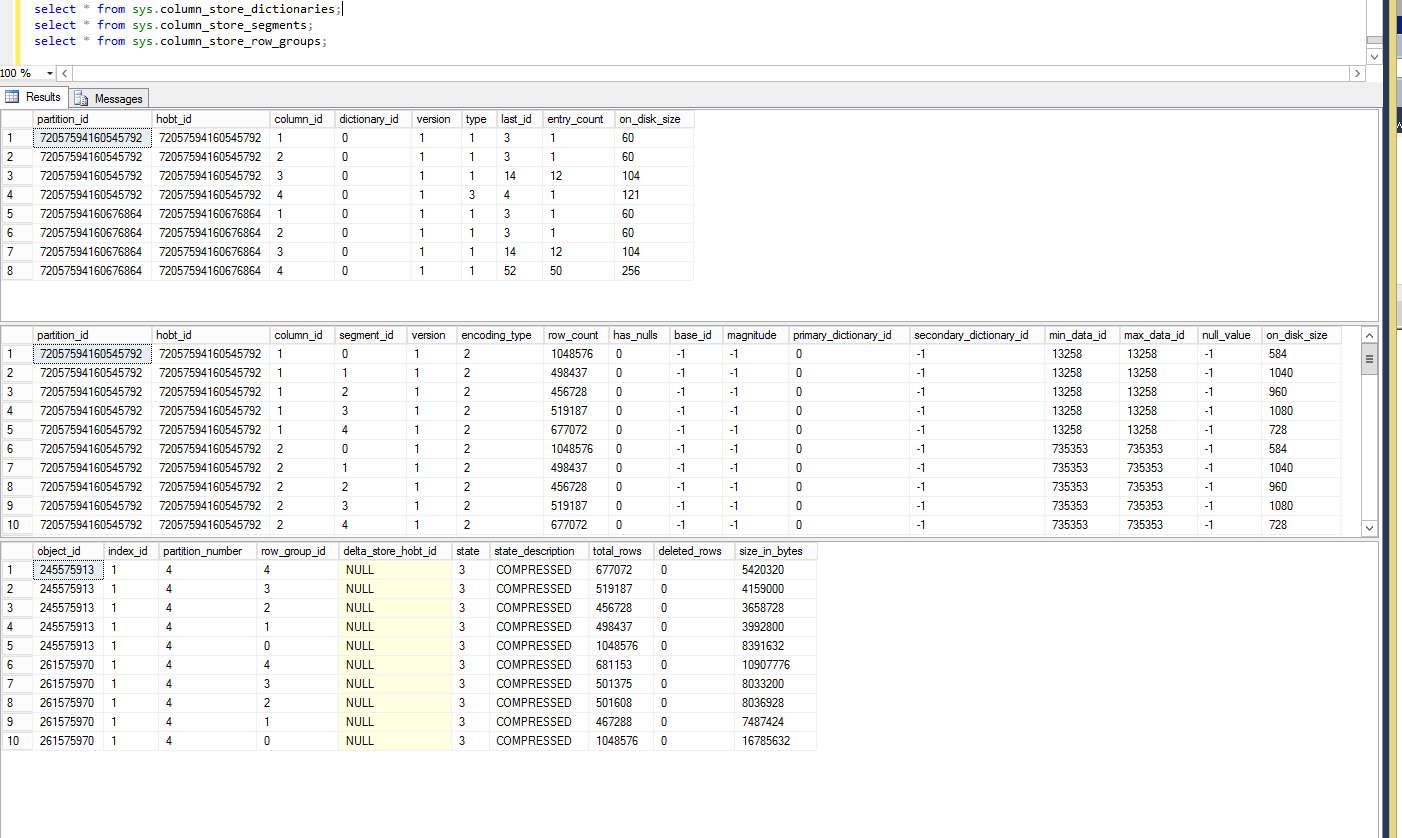
Let’s do it again:
-- create the empty rowset from the table we will switch into
select top 0 * into dbo.B_Phoebix_13267 from dbo.B_Phoebix
select top 0 * into dbo.S_Phoebix_13267 from dbo.S_Phoebix
--do ourselves a favour and make this temporary table as small as possible
--and add page compression
ALTER TABLE dbo.B_Phoebix_13267 REBUILD WITH (DATA_COMPRESSION = PAGE)
ALTER TABLE dbo.S_Phoebix_13267 REBUILD WITH (DATA_COMPRESSION = PAGE)
--empty rowset is created on primary by default
--move to the filegroup the partitioned table is on
ALTER TABLE dbo.B_Phoebix_13267 ADD CONSTRAINT CONS_dbo_B_Phoebix_13267 PRIMARY KEY (Id) on FGPhoebix
ALTER TABLE dbo.S_Phoebix_13267 ADD CONSTRAINT CONS_dbo_S_Phoebix_13267 PRIMARY KEY (Id) on FGPhoebix
-- we don't need it (or can even keep it as we are adding CCI)
ALTER TABLE dbo.B_Phoebix_13267 DROP CONSTRAINT CONS_dbo_B_Phoebix_13267
ALTER TABLE dbo.S_Phoebix_13267 DROP CONSTRAINT CONS_dbo_S_Phoebix_13267
--add constraint on temp table so that we can switch in to main table
ALTER TABLE dbo.B_Phoebix_13267 WITH CHECK ADD CONSTRAINT CK_B_Phoebix_13267 CHECK (([Id]=(13267)))
ALTER TABLE dbo.S_Phoebix_13267 WITH CHECK ADD CONSTRAINT CK_s_Phoebix_13267 CHECK (([Id]=(13267)))
--add data to temp table from loading tables
--remember IRL this would be SSIS or HPC or data loader of choice
INSERT INTO dbo.B_Phoebix_13267 (Id, monthEndDate, memberId, bsKey, value)
select Id, monthEndDate, memberId, bsKey, value
from dbo.B_Phoebix_Load WITH (NOLOCK)
where id = 13267
INSERT INTO dbo.S_Phoebix_13267 (Id, monthEndDate, memberId, sbId, flow, vesting)
select Id, monthEndDate, memberId, sbId, flow, vesting
from dbo.S_Phoebix_Load WITH (NOLOCK)
where id = 13267
--add CCI
CREATE CLUSTERED COLUMNSTORE INDEX [PK_B_Phoebix_13267] ON dbo.B_Phoebix_13267 WITH (DROP_EXISTING = OFF)
CREATE CLUSTERED COLUMNSTORE INDEX [PK_S_Phoebix_13267] ON dbo.S_Phoebix_13267 WITH (DROP_EXISTING = OFF)
--now we have CCI objects all pertaining to temp table
select * from sys.column_store_dictionaries;
select * from sys.column_store_segments;
select * from sys.column_store_row_groups;
--switch in to main table
ALTER TABLE dbo.B_Phoebix_13267 SWITCH TO dbo.B_Phoebix PARTITION $PARTITION.pfnPhoebix(13267)
ALTER TABLE dbo.S_Phoebix_13267 SWITCH TO dbo.S_Phoebix PARTITION $PARTITION.pfnPhoebix(13267)
And once more seeing as we have the data:
-- create the empty rowset from the table we will switch into
select top 0 * into dbo.B_Phoebix_13278 from dbo.B_Phoebix
select top 0 * into dbo.S_Phoebix_13278 from dbo.S_Phoebix
--do ourselves a favour and make this temporary table as small as possible
--and add page compression
ALTER TABLE dbo.B_Phoebix_13278 REBUILD WITH (DATA_COMPRESSION = PAGE)
ALTER TABLE dbo.S_Phoebix_13278 REBUILD WITH (DATA_COMPRESSION = PAGE)
--empty rowset is created on primary by default
--move to the filegroup the partitioned table is on
ALTER TABLE dbo.B_Phoebix_13278 ADD CONSTRAINT CONS_dbo_B_Phoebix_13278 PRIMARY KEY (Id) on FGPhoebix
ALTER TABLE dbo.S_Phoebix_13278 ADD CONSTRAINT CONS_dbo_S_Phoebix_13278 PRIMARY KEY (Id) on FGPhoebix
-- we don't need it (or can even keep it as we are adding CCI)
ALTER TABLE dbo.B_Phoebix_13278 DROP CONSTRAINT CONS_dbo_B_Phoebix_13278
ALTER TABLE dbo.S_Phoebix_13278 DROP CONSTRAINT CONS_dbo_S_Phoebix_13278
--add constraint on temp table so that we can switch in to main table
ALTER TABLE dbo.B_Phoebix_13278 WITH CHECK ADD CONSTRAINT CK_B_Phoebix_13278 CHECK (([Id]=(13278)))
ALTER TABLE dbo.S_Phoebix_13278 WITH CHECK ADD CONSTRAINT CK_s_Phoebix_13278 CHECK (([Id]=(13278)))
--add data to temp table from loading tables
--remember IRL this would be SSIS or HPC or data loader of choice
INSERT INTO dbo.B_Phoebix_13278 (Id, monthEndDate, memberId, bsKey, value)
select Id, monthEndDate, memberId, bsKey, value
from dbo.B_Phoebix_Load WITH (NOLOCK)
where id = 13278
INSERT INTO dbo.S_Phoebix_13278 (Id, monthEndDate, memberId, sbId, flow, vesting)
select Id, monthEndDate, memberId, sbId, flow, vesting
from dbo.S_Phoebix_Load WITH (NOLOCK)
where id = 13278
--add CCI
CREATE CLUSTERED COLUMNSTORE INDEX [PK_B_Phoebix_13278] ON dbo.B_Phoebix_13278 WITH (DROP_EXISTING = OFF)
CREATE CLUSTERED COLUMNSTORE INDEX [PK_S_Phoebix_13278] ON dbo.S_Phoebix_13278 WITH (DROP_EXISTING = OFF)
--now we have CCI objects all pertaining to temp table
select * from sys.column_store_dictionaries;
select * from sys.column_store_segments;
select * from sys.column_store_row_groups;
--switch in to main table
ALTER TABLE dbo.B_Phoebix_13278 SWITCH TO dbo.B_Phoebix PARTITION $PARTITION.pfnPhoebix(13278)
ALTER TABLE dbo.S_Phoebix_13278 SWITCH TO dbo.S_Phoebix PARTITION $PARTITION.pfnPhoebix(13278)
select * from sys.column_store_dictionaries;
select * from sys.column_store_segments;
select * from sys.column_store_row_groups;
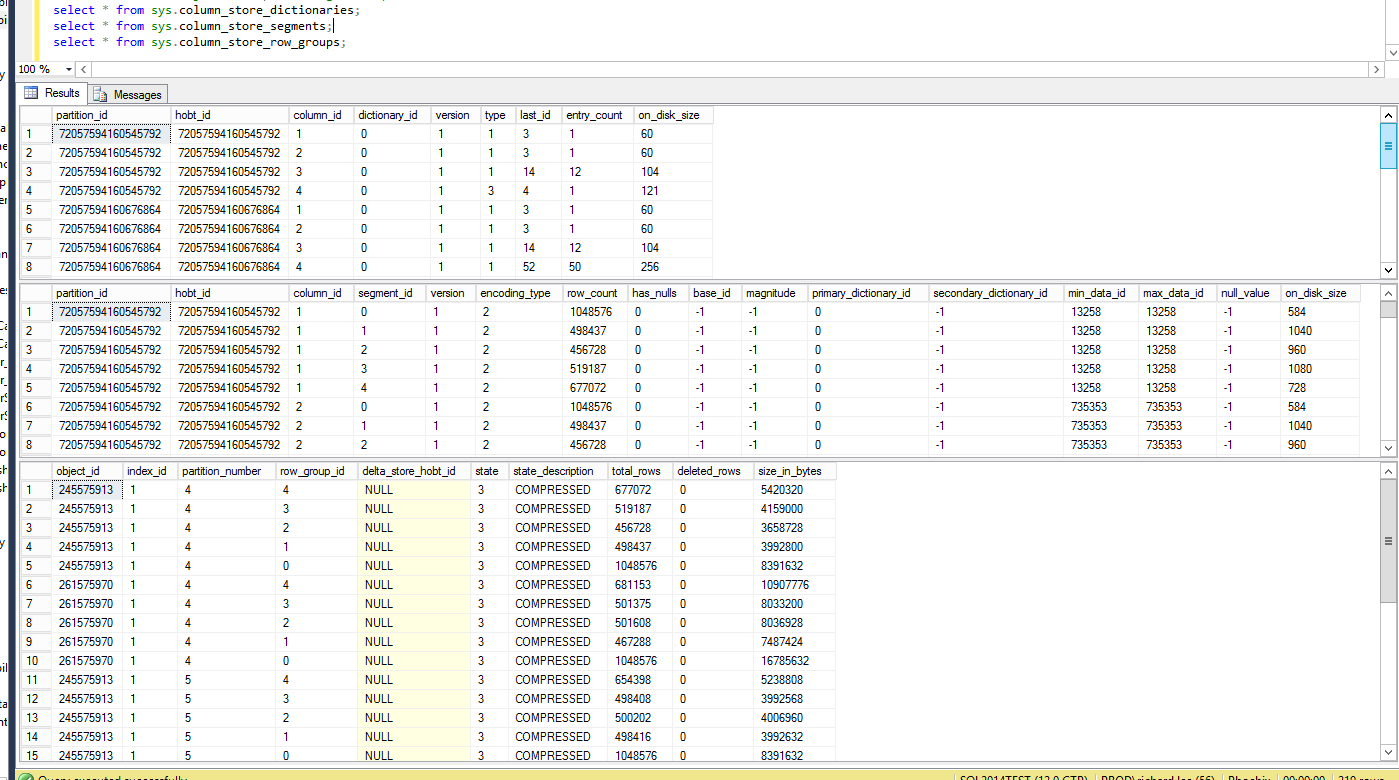
Below are two queries for checking the catalog views for both dictionaries and segments and grouping them by partition
COUNT(*) AS number_of_segments
FROM sys.column_store_segments AS s
INNER JOIN sys.partitions AS p
ON s.hobt_id = p.hobt_id
INNER JOIN sys.indexes AS i
ON p.object_id = i.object_id
WHERE i.type = 5
GROUP BY i.name, p.object_id, p.index_id, i.type_desc, partition_number ;
GO
SELECT i.name, p.object_id, p.index_id, i.type_desc, p.partition_number,
COUNT(*) AS number_of_dictionaries
FROM sys.column_store_dictionaries AS s
INNER JOIN sys.partitions AS p
ON s.hobt_id = p.hobt_id
INNER JOIN sys.indexes AS i
ON p.object_id = i.object_id
WHERE i.type = 5
GROUP BY i.name, p.object_id, p.index_id, i.type_desc, p.partition_number
GO
So there we go; a method to have optimised row groups without having to frequently rebuild the CCI on a massive single table. The same would also work for deletion; providing you want to delete an entire import you can switch out to a temporary table and drop and the delete bitmap would not be used in this case. Seeing as we still have hte temp tables we can switch out to these, drop them, and then check the views again.
ALTER TABLE [dbo].[B_Phoebix_13278] DROP CONSTRAINT [CK_B_Phoebix_13278]
ALTER TABLE [dbo].[S_Phoebix_13278] DROP CONSTRAINT [CK_S_Phoebix_13278]
ALTER TABLE [dbo].[B_Phoebix] SWITCH PARTITION $PARTITION.pfnPhoebix(13278) TO [dbo].[B_Phoebix_13278]
ALTER TABLE [dbo].[S_Phoebix] SWITCH PARTITION $PARTITION.pfnPhoebix(13278) To [dbo].[S_Phoebix_13278]
DROP TABLE [dbo].[B_Phoebix_13278]
DROP TABLE [dbo].[S_Phoebix_13278]
DROP TABLE [dbo].[B_Phoebix_13258]
DROP TABLE [dbo].[S_Phoebix_13258]
select * from sys.column_store_dictionaries;
select * from sys.column_store_segments;
select * from sys.column_store_row_groups;
The row groups, segments and dictionaries have all been dropped for those partitions, so there’s no need to rebuild the CCI.
Resources: