
Clustered Columnstore Updates
Recently the SQLCAT team published a post on their blog titled Data Loading performance considerations with Clustered Columnstore indexes. In it they talk of loading data into partitioned tables where the load is aligned. Interestingly, their recommended process is to load into a staging table with the clustered columnstore index created first.
This is still based on the fact that you can hit the magic number of 1,048,576, or at the very least 102,400, per bulk insert, to create compressed segments. If you cannot, then I still feel that the method of loading into a heap, and then creating the clustered columnstore index, is preferential. This is because if you trickle insert into a CCI, you will end up with a mixture of open/closed delta stores and come compressed segments. You could leave it to the tuple mover to compress these, and you would still be left with some open delta stores. However, as Remus Rusanu points out, this is not recommended. To complete the process quickly, and to remove any open delta stores, you would need to rebuild the partition.
It is worth noting though that the SQLCAT team also looks into data loading times on a heap (WITH TABLOCK) against a CCI object, and shows that inserting into a CCI is slower than a heap, because compression. And so if you cannot create compressed segments and need to rebuild the index post-insert, why bother with this slower insert rate into delta stores and then rebuild the entire index when you can get faster insert times into a heap, and then create the CCI at the end, with the same outcome.
Just to clarify here, I’m not knocking the SQLCAT findings, or saying that they are wrong, it’s just that for those scenarios where it’s impossible to increase the number of inserts to a number where compressed columnstore objects are created, inserting into heaps then creating CCI objects removes a lot of issues. If you use something like HPC for example, you could find this occuring. If you find that creating CCI on tables monopolises resources on the server, then use resource govenor to limit the amount of memory used when creating CCI.
Another section of the post focuses on ordering the data in a CCI to improve query performance. This can assist in eliminating segments from being scanned for a given query, if you order the data by the required predicate. Currently, it is not possible to order the data when creating a CCI, however it is possible to create a clustered index ordering on the required columns, and then creating the CCI with the option DROP_EXISTING = ON to remove the original row store clustered index. So the process is:
Create a table and load some data into it. When I say “some” I really mean 20+ million rows. I will upload the .bak file so that you don’t have to load the data, saving some 40 minutes. After the data loading we create the clustered columnstore index.
--**************************************
-- Table definition
--**************************************
create table [dbo].[CciDemo](
[Id] [int] IDENTITY(1,1),
[WatchDate] [date] NOT NULL,
[associateId] [bigint] NOT NULL,
[OsKey] [varchar] (4) NOT NULL,
[value] [int] NOT NULL
)
GO
--**************************************
-- Insert the rows
--**************************************
declare @i as int;
set @i = 1;
begin tran
while @i <= 2345678
begin
insert into dbo.CciDemo
([WatchDate], [associateId],[OsKey],[value] )
values
( GETDATE(), RAND ()*12, 'FFOS', RAND ()*13),
( GETDATE(), RAND ()*12, 'FFOS', RAND ()*13),
( GETDATE(), RAND ()*12, 'FFOS', RAND ()*13),
( GETDATE(), RAND ()*12, 'FFOS', RAND ()*13),
( GETDATE(), RAND ()*12, 'FFOS', RAND ()*13),
( GETDATE(), RAND ()*12, 'FFOS', RAND ()*13),
( GETDATE(), RAND ()*12, 'FFOS', RAND ()*13),
( GETDATE(), RAND ()*12, 'FFOS', RAND ()*13),
( GETDATE(), RAND ()*12, 'FFOS', RAND ()*13),
( GETDATE(), RAND ()*12, 'FFOS', RAND ()*13)
set @i = @i + 1;
end;
commit;
--**************************************
-- Creating our Clustered Columnstore Index
--**************************************
create clustered columnstore index CCI_CciDemo
on dbo.CciDemo;
GO
Now if we query the segments DMV and check the distribution ofthe minimum and maximum values in compressed segment, we can get an idea of the dispersement of the values in the first column are.
select segment_id, row_count, base_id, min_data_id, max_data_id
FROM sys.column_store_segments AS s
INNER JOIN sys.partitions AS p
on s.partition_id = p.partition_id
where column_id = 1
and p.object_id = object_id('CciDemo')
order by min_data_id, max_data_id;
GO
We can see that the minimum values seem pretty consistent. This is due in part to the loading and the fact that the column is an ident column. The maximum id’s in each segments however are spread all across the segments. In the screenshot below, segment 21 stores a wide range of values which overlaps considerably with segment 16. So for pretty much any value against the id column would have to scan these segments whether or not they hold the value. This is because SQL does not know what values are in this segment, just that a range between minimum and maximum is stored.

As an aside, lets look at the total number of segments created. 42! That’s a lot for a 23 million row table. Surely we’d expected about 21 segments of 1048576?
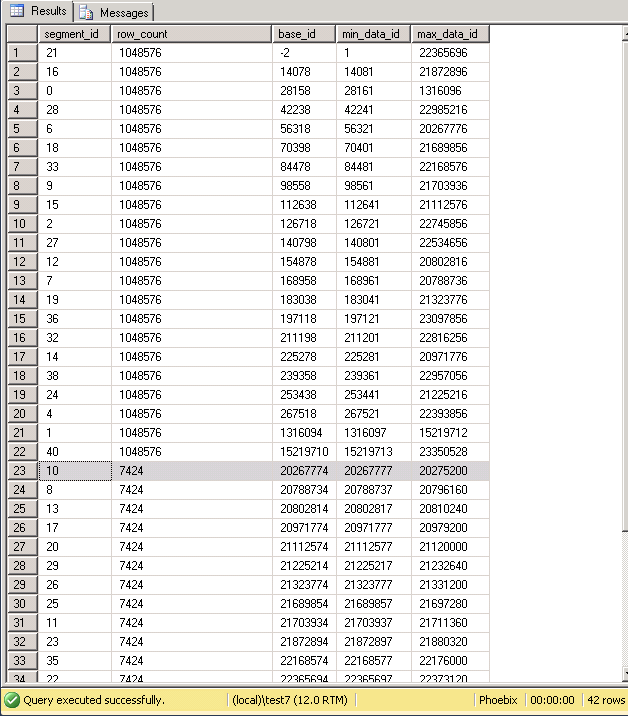
Well the last ones created had considerably fewer rows than that. This is because the task to create the CCI was a parallel process, resulting in smaller compressed segments being created across multiple cores at the same time to make the operation more efficient. This is not wrong: this is exactly what we told the database engine to do, but it is not ideal. To “fix” this, we can set the MAXDOP to 1 during a rebuild. Of course, this takes a lot longer than previous, but we end up with optimal segments.
ALTER INDEX [CCI_CciDemo] ON [dbo].[CciDemo] REBUILD PARTITION = ALL WITH (DATA_COMPRESSION = COLUMNSTORE, MAXDOP = 1)
GO
select segment_id, row_count, base_id, min_data_id, max_data_id
FROM sys.column_store_segments AS s
INNER JOIN sys.partitions AS p
on s.partition_id = p.partition_id
where column_id = 1
and p.object_id = object_id('CciDemo')
order by min_data_id, max_data_id;
GO
23 rows is a lot tider, however if we wanted to eliminate segments from querying, the ordering is still suboptimal.

Now let’s follow the SQLCAT advice of creating an ordered clustered index on the table, and then creating a CCI whilst dropping the clustered index and check the segments again.
DROP INDEX [CCI_CciDemo] ON [dbo].[CciDemo] WITH ( ONLINE = OFF )
GO
CREATE CLUSTERED INDEX [CCI_CciDemo] ON [dbo].[CciDemo]
(
[Id] ASC
) with (DATA_COMPRESSION = PAGE)
GO
create clustered columnstore index CCI_CciDemo
on dbo.CciDemo WITH (DROP_EXISTING=ON);
GO
select segment_id, row_count, base_id, min_data_id, max_data_id
FROM sys.column_store_segments AS s
INNER JOIN sys.partitions AS p
on s.partition_id = p.partition_id
where column_id = 1
and p.object_id = object_id('CciDemo')
order by min_data_id, max_data_id;
GO
In my results it was still not great. I am back to having more segments than necessary (39 this time), plus the ordering has completely gone.
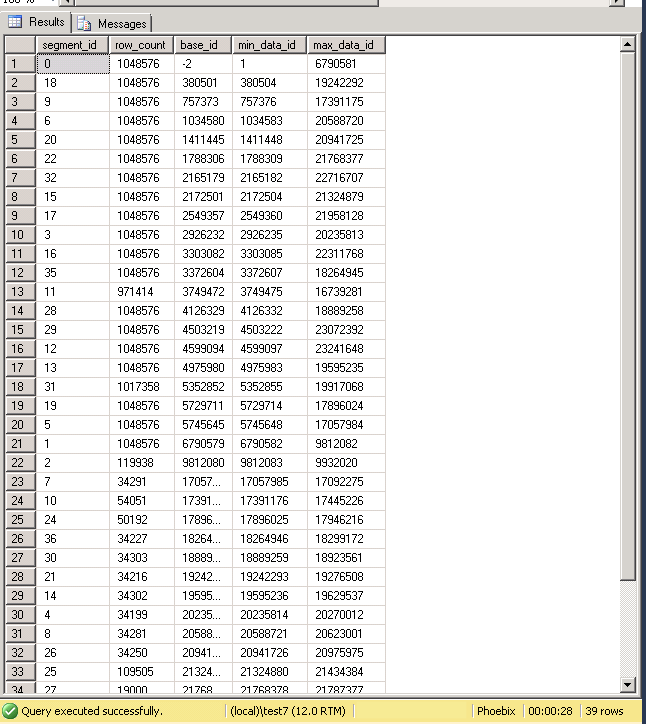
To fix this, let’s drop the index, create the ordered clustered index again, and then create the CCI with DROP_EXISTING on and MAXDOP set to 1.
DROP INDEX [CCI_CCiDemo] ON [dbo].[CciDemo] WITH ( ONLINE = OFF )
GO
CREATE CLUSTERED INDEX [CCI_CciDemo] ON [dbo].[CciDemo]
(
[Id] ASC
) with (DATA_COMPRESSION = PAGE)
GO
create clustered columnstore index CCI_CciDemo
on dbo.CciDemo WITH (DROP_EXISTING=ON, MAXDOP = 1);
GO
select segment_id, row_count, base_id, min_data_id, max_data_id
FROM sys.column_store_segments AS s
INNER JOIN sys.partitions AS p
on s.partition_id = p.partition_id
where column_id = 1
and p.object_id = object_id('CciDemo')
order by min_data_id, max_data_id;
GO
This time we have both optimal numbers of compressed segments, plus perfect distribution of the values available in each segment.

Clearly creating CCI on one core is going to take a lot longer than across multiple cores, plus creating a clustered index is going to increase the data loading time, so it’s important test that this brings you a net benefit. By this I mean that ordering may result in faster queries, but if the time taken to create the clustered index is greater than the time saved in querying the data, particularly if the query is run once to load the data into a cube, then it’s really not worth it.
With regards to the poor distribution of rows stored in compressed segments; you can set maxdop, or you could use resource govenor to control this. This scenario is a bit extreme as I was runinng the example on a 24 cores box with 24 million rows, but it highlights the point that you cannot assume that all compressed segments are optimal, and so you need to check to make sure that this is the case. Extended events help cover the issues highlighted here.
If you would like to see the parallelised building of CCI take into account order, then I have good news: this Connect issue suggests that it will appear in the next version of SQL Server.
Speaking of Connect issues, here is one related to Clustered Columnstore Indexes I came across when raising a suggestion myself: Clustered columnstore uses its own cache, not the buffer pool. This cache has low priority compared to the buffer pool itself, and the performance of queries against CCI object can suffer when the buffer pool has grown large. A really good example of this, and a corresponding Connect issue, was posted a few days ago here. If you use CCI its certainly worth downloading the example and if you agree that CCI objects should be cached the same as row based tables then consider giving the issue an up-vote. For me it is worth a vote, however in my experience decisions made by the SQL development team are hardly arbitrary; there’s most likely a perfectly reasonable explanation for why the columnstore cache has a lower priority than the buffer pool. But at any rate I have up-voted the issue. Hopefully enough up-votes would at least warrant a response as to why the columnstore cache has a lower priority.