
Databricks InferSchema Performance
Hello!
One of the really handy features when reading a csv in Databricks is being able to infer a schema from the contents of the file; that way you do not need to declare a schema up front, so if the contents of the file changes you still inherit what is in there. There is however an inevitable tradeoff, because the file has to be read for the datatypes of each column to be ascertained. In some technologies that include an inferSchema option, the file is sampled. But as I understand it, according to the documentation, the sample rate is 100%:
This function will go through the input once to determine the input schema if inferSchema is enabled. To avoid going through the entire data once, disable inferSchema option or specify the schema explicitly using schema.
So where you have a large file, you will find that it can take longer to load a file into a dataframe.
But how much longer?
Using the databrick-samples I grabbed the amazon customers csv. This file contains only one column, an int, but it contains quite a few rows. 24,013,668 to be exact. So if I were to infer a schema against a file this big, and then provide a schema, how much faster would that be?
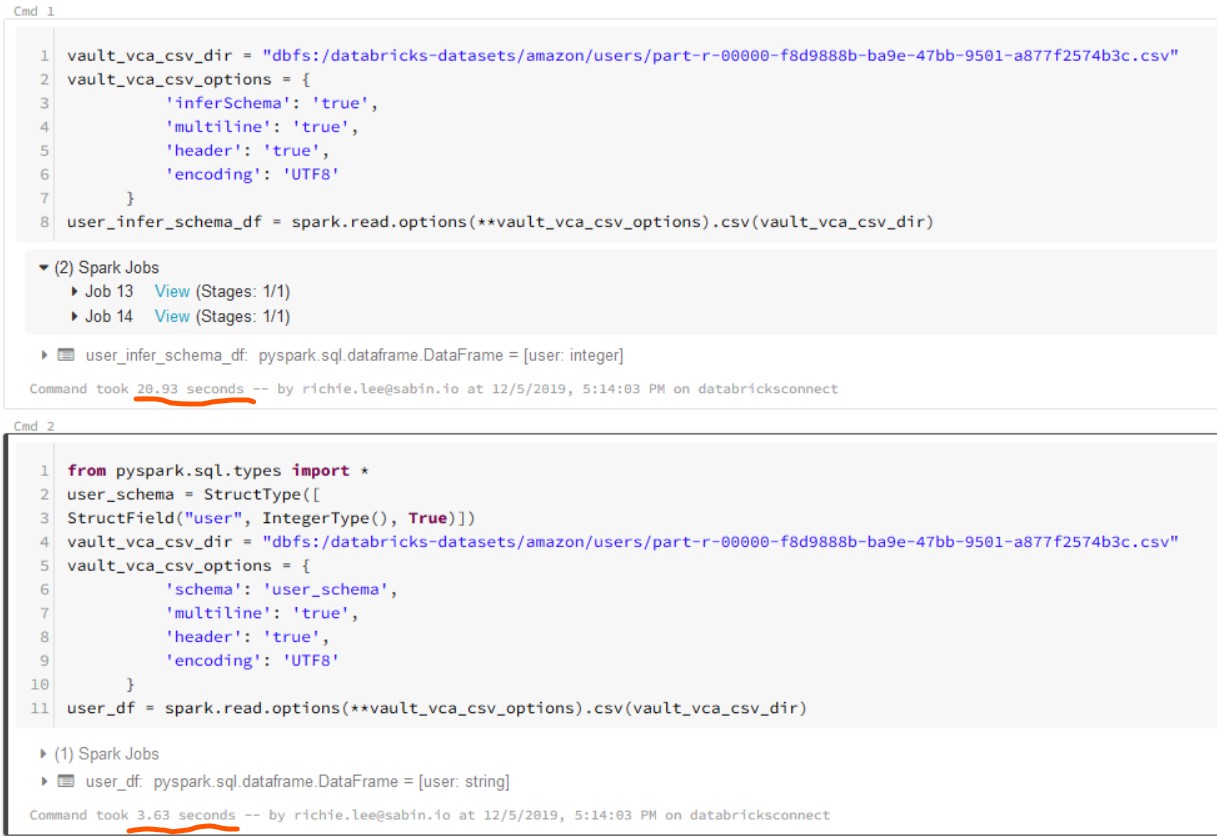
That’s some performance gain there! Against real production data, I’ve seen the gain be even greater, from 5 minutes to 20 seconds. And if you drill down into the DAG you will notice that the inferschema cell has two operations, which reads the entire file.
This here is the notebook source code to test out for yourselves.
# Databricks notebook source
vault_vca_csv_dir = "dbfs:/databricks-datasets/amazon/users/part-r-00000-f8d9888b-ba9e-47bb-9501-a877f2574b3c.csv"
vault_vca_csv_options = {
'inferSchema': 'true',
'multiline': 'true',
'header': 'true',
'encoding': 'UTF8'
}
user_infer_schema_df = spark.read.options(**vault_vca_csv_options).csv(vault_vca_csv_dir)
# COMMAND ----------
from pyspark.sql.types import *
user_schema = StructType([
StructField("user", IntegerType(), True)])
vault_vca_csv_dir = "dbfs:/databricks-datasets/amazon/users/part-r-00000-f8d9888b-ba9e-47bb-9501-a877f2574b3c.csv"
vault_vca_csv_options = {
'multiline': 'true',
'header': 'true',
'encoding': 'UTF8'
}
user_df = spark.read.options(**vault_vca_csv_options).csv(vault_vca_csv_dir,schema=user_schema)